
Hadoop
Introduction
Hadoop is a distributed system created based on google’s GFS, the reason for the creator to create Hadoop is because when the creator creates lucene search engine he found there are huge amount of data needs to be stored into distributed system to be searched.
Hadoop is a system that consists several sub-systems, like HDFS the file system, MapReduce the computation system and yarn the resource scheduler along with additional projects like Pig, Hive, Sqoop, etc.
Different queues
There are several advantages of using AWS SQS service, it’s fully managed service which means you don’t have to worry about the duribility and scalability of the service, of course you don’t have to manage the server. SQS is generally used to decouple your architecture which provides more reliable system. SQS provides two types of message queue, one is standard queue, standard queue guarantees at-least-once message delivery. Therefore, when your application requires the sensitivity of delivery once message, you have to choose FIFO queue. What’s more, standard queue will do its best to keep the message deliver in order. However, there is no guarantee for the order. Generally to say, standard queue provides a simple queue service, it can be used in an application without the restriction of delivery order and times. In the contrary, FIFO queue supports strong ordering and exactly-once message delivery. Hence, if your application has these restrictions you’d better choose FIFO queue. Another important feature of SQS is that if you have several clients want to get a message, SQS is not the proper service to pick, instead using SNS.
SQS key attributes
There are several important settings worth to know when you creating a new queue.
 First of all, default visibility timeout is an important property. Here is
an image that from the aws official documents can help me explain it well.
First of all, default visibility timeout is an important property. Here is
an image that from the aws official documents can help me explain it well.
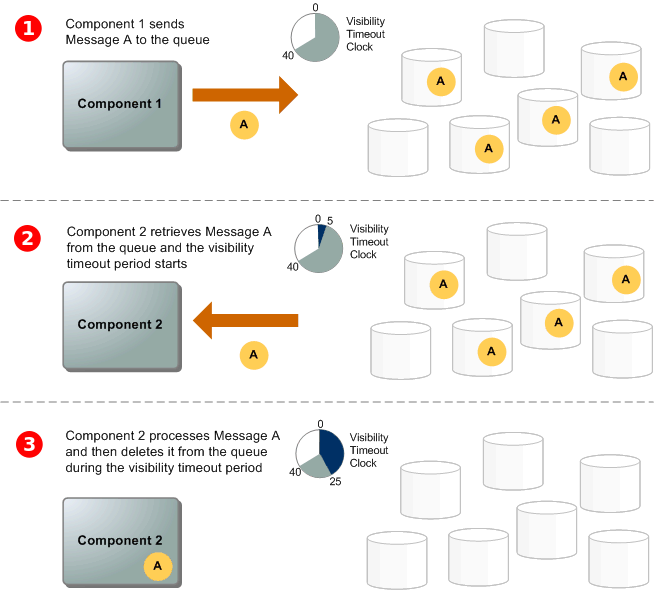
when you push a message into the queue, the message will be copied into several servers (high availibity). Then the message is sitting there waiting for other service to pick (EC2, lambda, etc.). Whenever there is a service picking the message the visibility time out clock starts count while the message is not visible any more. Suppose the task (message) can be finished in the timeout peroid, the message will be deleted from the queue. Therefore, best practice to setup this timeout is setting it greater than the task processing time, otherwise, while the task is still processing, when the visibility timeout ends, this message will be visible by another service (process) which cause duplicated processing.
Next two settings are simple, message retention period is the max time the queue can keep the message while no process picks it. And maximum message size is simply as the name says the max message size. Delivery delay is the time that when a message reach the queue, the message will be freezed from this amount of time, notice this time is applied for every new reached message. Next import attribute is receive message wait time, this attribute sometimes is referred as long polling. It works as following, whenever there is new process trying to pick a message, when this attribute is setting as 0, if the process finds the queue is empty, it will not wait for the new message arrives, the process will immediately shutdown the connection, in such scenaro, unnecessary connections will be established multiple times which costs extra billing. Therefore, normally we will set the value more than 0.
Dead letter queue
dead letter queue is another queue you have to associate with a queue you have created. Which used to store those messages cannot be processed by that queue. For example, you can create another process which has more CPU and memory power to process the message that cannot be processed from the standard queue. What’s more, you might want to use dead letter queue to diagnose why the message cannot be processed in the standard queue. There is only one important attribute, maximum receives, this attribute is used to determine after how many processes tried the message failed, then put the message into the dead letter queue.
About the encryption option, please refer my another article called AWS KMS
Other attributes
 when turn on the functionality of content-based deduplication. The duplicated
message will be removed automatically by the queues. Message available is
the metric that shows amount of messages that you pushed into the queue and
Messages in Flight is the total amount of messages that is processing.
when turn on the functionality of content-based deduplication. The duplicated
message will be removed automatically by the queues. Message available is
the metric that shows amount of messages that you pushed into the queue and
Messages in Flight is the total amount of messages that is processing.
There are several scenarios a SQS queue can be used, normally combine SQS queue
with lambda is a good practice, you can trigger a lambda function whenever there
is a new message arrives the queue.

Another use case is combining SQS with SNS service to create a fan out architecture.
Because, SQS can guarantee the message comes from a unique resource, whereas SNS
can response the multiple delivery work.
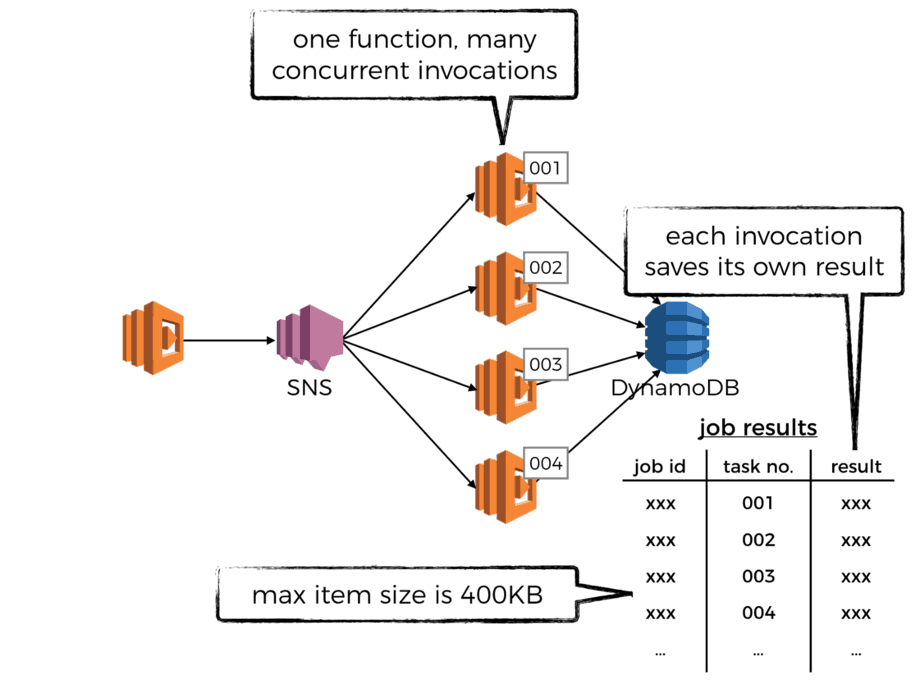
the image above shows such architecture, the leftmost is the SQS service, the middle one is SNS service, suppose you have one message that has to be processed by different services, maybe one service is doing filtering, another service is for storing this message.